基本信息
- 年份:2019
- 期刊:arxiv
- 标签:PolSAR, Complex
- 数据:PolSAR图像数据
创新点
- 使用了复数域的卷积操作
- 为了利用少量标记样本实现精确定位和快速分类,提出了一种将Cs-CNN权重直接迁移到C-Dilated CNN中
- 设计了一种由C-Dilated CNN和复数域encoder-decoder网络组成的a pixel-refining parallel mapping network in the complex domain(CRPM-Net)来提取上下文语义特征,并对错误分类的训练像素进行纠正以获得更高的准确率。
创新点来源
对于PolSAR图像分类,传统方法主要分为两个步骤:特征提取和训练分类器。这种方法通常正确率不是很高。而基于深度学习的方法主要分为两种:
- 通过pixel by pixel的方式实现对PolSAR图像的精准分类。但是这种方法在提取相邻像素特征的时候需要消耗大量的重复计算,在高分辨率图像上浪费大量的时间。
- 基于pixel mapping network的方式(如FCN、Segnet等)通过在encoder-decoder结构直接对整张图进行pix-to-pix的像素映射分类,可以解决上述问题。但是这种方法需要输入图像对应的ground truth,而PolSAR图像中ground truth包含大量的unlabeled像素。前人使用将ground truth中未标记的部分置为0来解决这个问题,但是会导致边缘很粗糙。
不像普通图像,PolSAR数据的协方差矩阵$C$和相干矩阵$T$都是在复数域中的,若直接使用复数域中的卷积操作可以提取到PolSAR图像的相位信息,结果也会更好。
为了进一步解决基于深度学习方法的现有问题,实现对PolSAR图像的高效且准确的分类,作者提出了a pixel-refining parallel mapping network in the complex domain (CRPM-Net) 。
主要内容
实数域的CNN
CNN主要由卷积层、激励层和池化层组成。示意图如下:
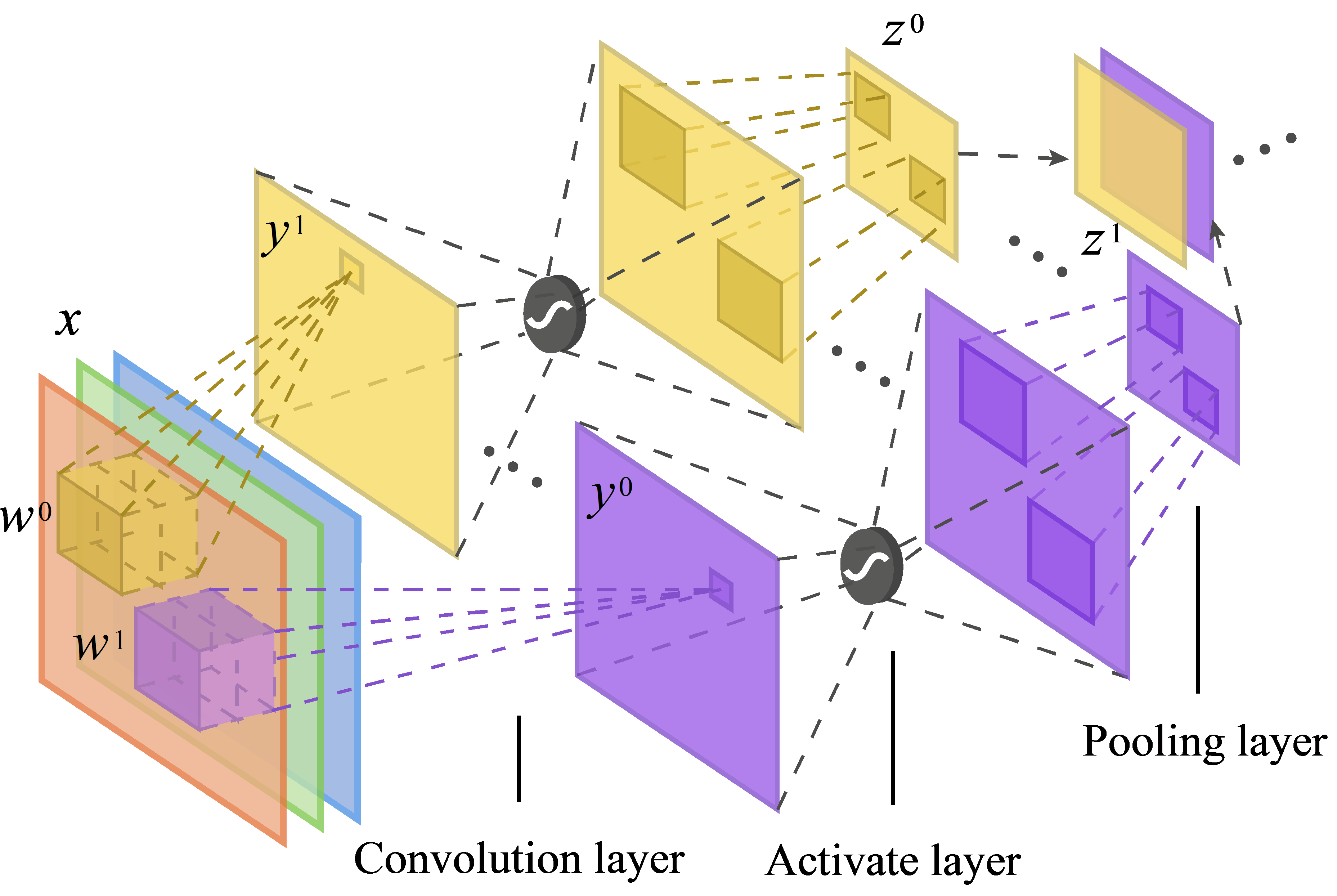
复数域的CNN
前向传播
假设复数域输入为$X$,维度为$m \times n \times c$,可以将其拆分为实数部分和虚数部分,如下所示:
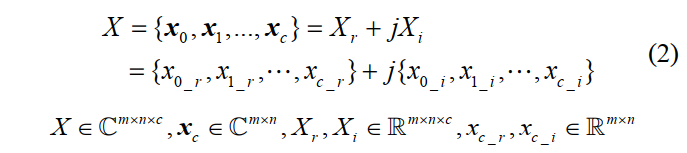
同样的,复数域的卷积核$W$也可以拆分为实数和虚数两部分。

可以看到输入$X$和卷积核$w_o$的通道数均为$c$。记实数域的卷积操作为$Conv(\cdot)$,复数域的卷积操作为${\mathbb C}conv(\cdot)$,则复数域卷积的第$o$个卷积核输出为:
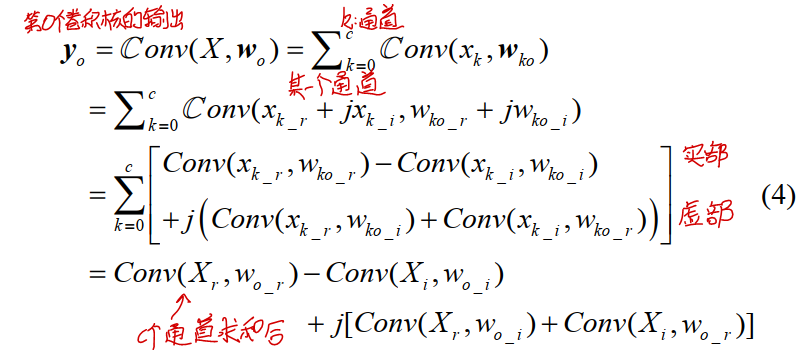
其中,$w_{o_r}$和$w_{o_i}$分别为第$o$个卷积核的实部和虚部部分,定义为:

从公式(4)中可以看到,其实复数域的卷积可以分为四部分,分别是$X_r$和$w_{o_r}$的普通卷积、$X_i$和$w_{o_r}$的普通卷积、$X_r$和$w_{o_i}$的普通卷积、$X_r$和$w_{o_i}$的普通卷积,如下图所示:
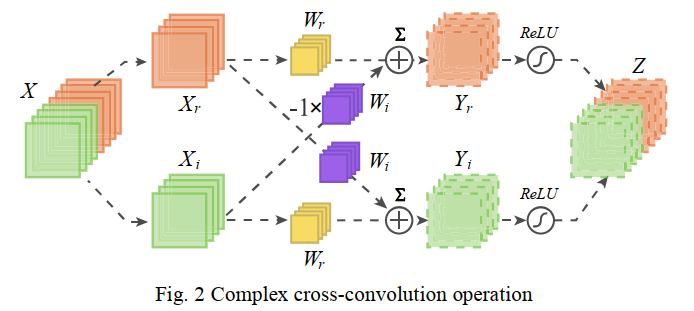
对于激励函数而言,分别对实部和虚部分别经过激励函数,复数域的ReLU激励函数为:
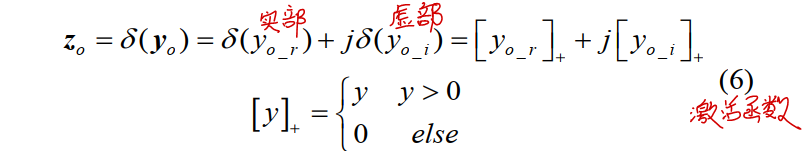
反向传播
损失函数关于$w_{ko}$(第$o$个卷积核第$k$个通道)的梯度为:
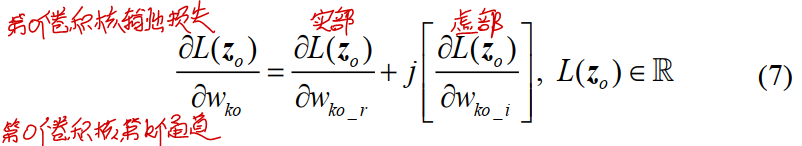
其中虚部可以通过如下方式计算:
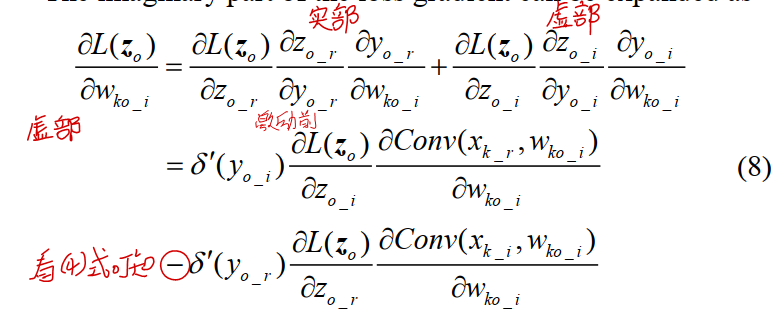
实部可以通过如下方式计算:

在求损失时,$w_{ko}$的负梯度如下所示:
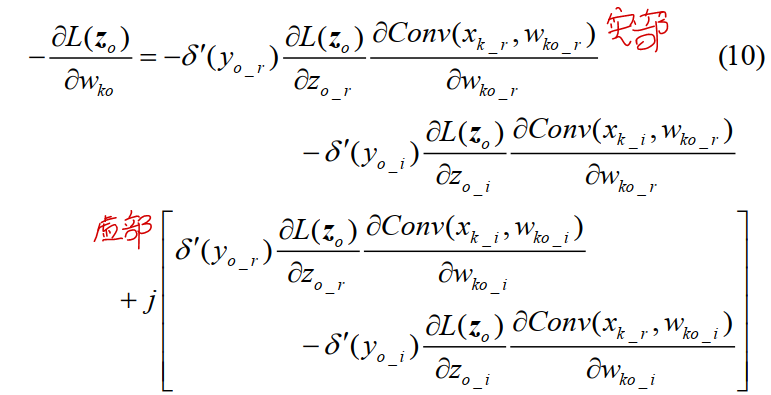
经过第$t$次迭代后,$w_{ko}^t$的更新方式如下,其中$\eta$ 为学习率:
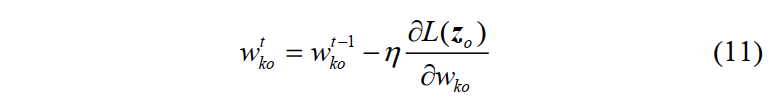
根据公式(10)可以看到,卷积核的实部和虚部是分别进行更新的。
Structure of Complex Cross-Convolution Neural Network
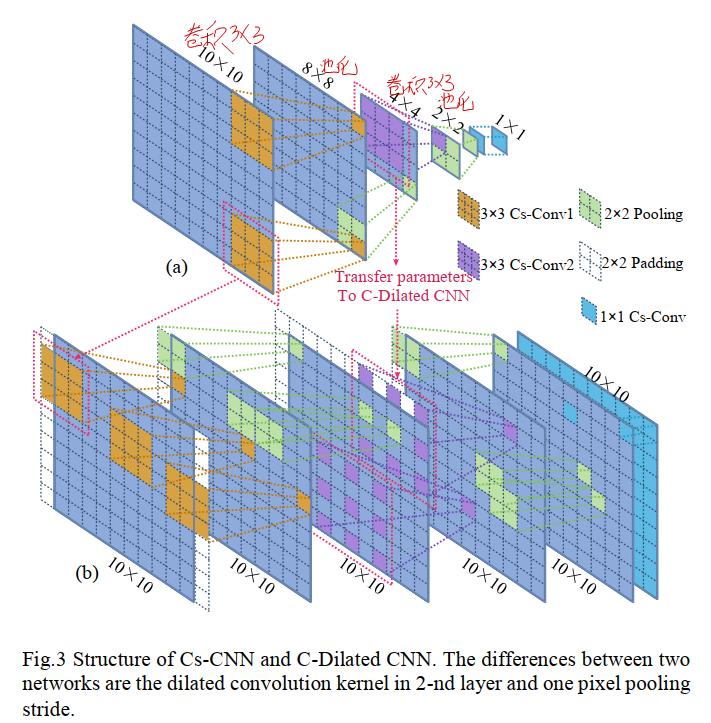
为了提取PolSAR图像的散射特征和相位信息,作者先使用了一个有三个卷积层的复数神经网络Cs-CNN,结构如图3(a)所示。结构分为为$3\times 3$卷积+$2 \times 2$最大池化、$3\times 3$卷积+$2 \times 2$最大池化、$1 \times 1$卷积。值得注意的是,这样的池化层的步长为2,卷积层和接下来要介绍的C-Dilated CNN中的卷积层均没padding操作,所以每次经过卷积后图像尺寸都会缩小2。最后一个$1 \times 1$卷积的作用是将48维度的特征向量映射到类别数维度。输入维度为$10 \times 10$,最终可以得到$1 \times 1$大小的复数特征图。为了将$1 \times 1$大小的复数特征图和真实的实值类标作对比得到损失,将$1 \times 1$大小的特征图拆分成实数部分、虚数部分、幅度部分、相位部分,然后紧跟一个$4 \times num_classes$的全连接层得到每一个类别的得分(论文说是大小为$4 \times 1$的全连接层,但是我认为这里应该写错了)。
Transfer Dilated Convolutional Neural Network in the complex domain
Cs-CNN在提取相邻像素特征的时候,会充斥着大量的重复计算,当处理整张图片的时候非常低效。为了提高Cs-CNN的速度,将它的参数迁移到一个复数域空洞卷积神经网络里,称为C-Dailated CNN,实现输入和输出类别的一一映射,如图3(b)所示。C-Dailated CNN和Cs-CNN主要有以下几个不同点:
第一个$3 \times 3$卷积层的padding从valid变成了same
第二个$3 \times 3$卷积层的padding从valid变成了same,且变成了空洞卷积,增加了感受野
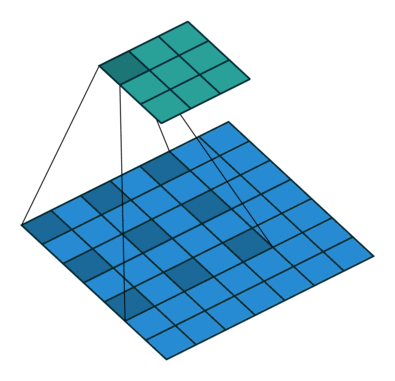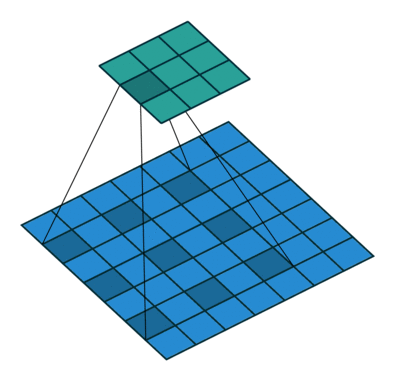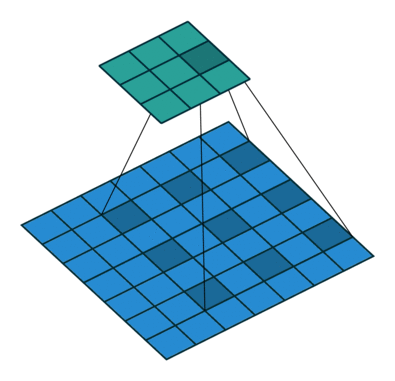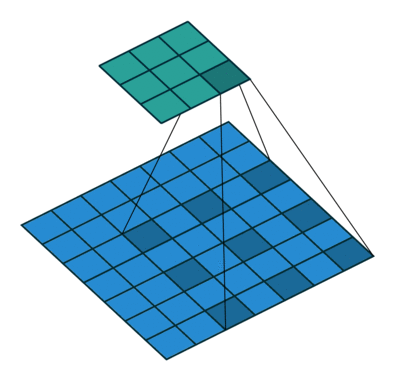
池化层的步长改为了1,且padding方式改为了same
通过上述更改,使得输入和输出的尺寸相同,可以实现对整个输入按照像素点分类,而Cs-CNN只能实现对一个点进行分类,所以加快了速度。当然直接这样迁移过来,会有一部分精度的损失,后面也有实验证明。
疑惑:
- 为什么只有第二个卷积改为了空洞卷积,猜测可能都变成空洞卷积结果会变得更差。
- Cs-CNN只对一个像素点进行分类,对应原图哪个像素点呢?高光谱分类通常取奇数大小的划窗,这样可以让其中心点作为整个划窗窗口的类别,这里是怎么处理的?答:如$8 \times 8$的邻域,则取左上大小为4,右下大小为3。
Encoder-Decoder Network in the complex domain
上面说了,直接将Cs-CNN的权重迁移到C-Dailated CNN中,虽然可以加快分类速度,但是相应的分类准确率有点下降,为了解决这个问题,作者引入了Encoder-Decoder结构,提取上下文信息。和C-Dailated CNN相同,复数域的Encoder-Decoder结构也能在考虑相位信息的情况下实现高效的pixel mapping分类,网络结构如图4(c)所示:
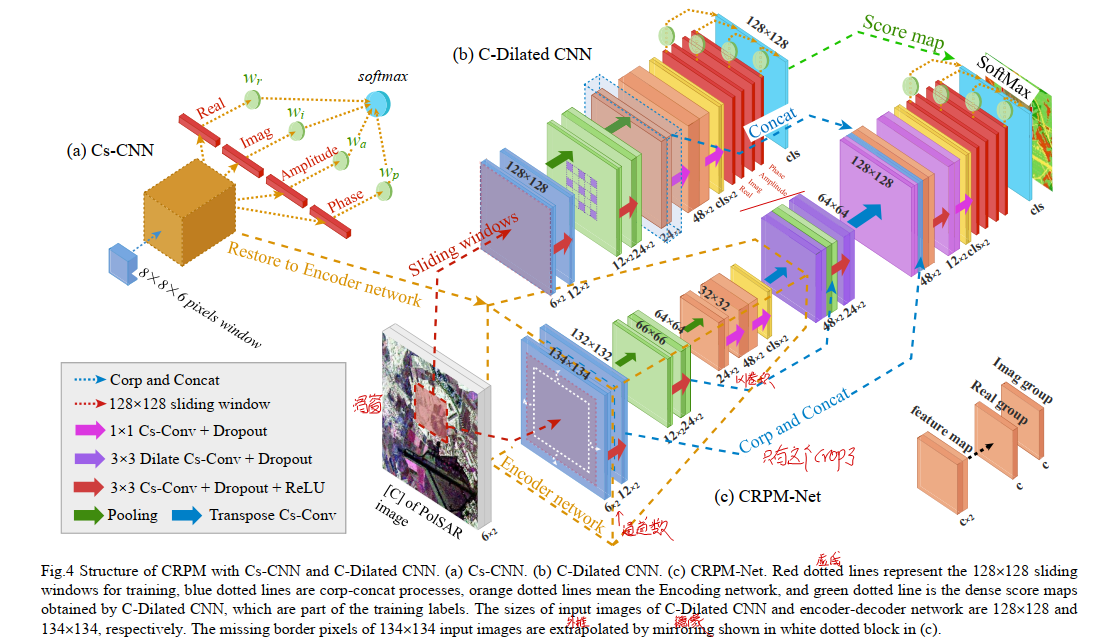
在PolSAR分类任务中,目标的上下文特征通常比较弱,除了稀疏的人工建筑物,如道路和建筑。因此Encoder-Decoder结构中卷积核的感受野不需要太大,只包含了和Cs-CNN相同的三个可训练的复数卷积层,特征图被4倍的下采样,为了实现pixel mapping,这里使用了两个反卷积操作。同样的使用$1 \times 1$的卷积将特征图的channel从48降到了num_classes。因为decoder操作会丢失很多地物的局部信息,导致结果比较操作,因此这里采用了和U-net相同的结构,将低层特征和高层特征沿着channel进行融合(若维度不同,则先进行crop操作),同样的因为卷积操作的存在会导致特征图越来越小,因此这里很简单的将输入图像尺寸的边界重复多次直到维度从$128 \times 128$变成了$134 \times 134$。
至于这里为什么直接从$128 \times 128$扩充到$134 \times 134$,而不是在卷积过程中进行补零,个人猜测这样可以更多的使用到PolSAR数据,分类更加精准。
Structure of CRPM-Net and Training Framework
为了兼顾定位精度(C-Dailated CNN)和上下文语义特征(Encoder-Decoder network),作者将C-Dailated CNN的24 channel特征图(也就是两个$3 \times 3$卷积后得到的特征图)和decoder网络的24 channel特征图拼接在一起,如图4(c)所示,即可得到CRPM-Net。
C-Dailated CNN和Encoder-Decoder network在训练过程中,都需要与输入大小相同的类标图,但是这个在PolSAR图像中通常无法得到,为了解决这个问题,作者提出了两阶段的训练方法:
- 使用少量的标记样本训练Cs-CNN网络,然后将Cs-CNN网络的权重迁移到C-Dailated CNN和Encoder-Decoder network中
- 使用Encoder-Decoder network提取上下文信息,并纠正Cs-CNN和C-Dailated CNN中分错的样本。
在实验中,拥有少量训练样本的类别通常很难进行分类,为了解决这个问题,作者使用了focal loss,将更多的注意力放在少量样本或者更大训练误差的样本上,假设Cs-CNN的复数输出值为$z’=\lambda e^{j \varphi}$,则focal loss的定义式如下:
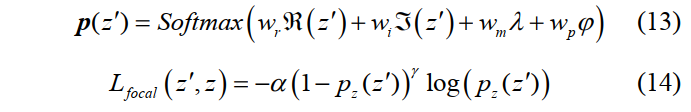
其中,$z$表示当前像素的真实类别,$p(z’) \in {\mathbb R}^{class_num}$,表示属于各个类别的概率,$\lambda、\varphi$分别表示幅度和相位,另外,个人觉得$w_r、w_i、w_m、w_p$的维度应该是$1 \times class_num$,这样才能实现softmax函数。而且个人觉得focal loss的表达式好像也有问题,缺了指示变量。
CRPM-Net的训练过程如下:


因为PolSAR图像中各个类别的种类数不同,因此这里针对不同类别采用了不同的采样频率,使得最终的各个类别的训练样本个数接近。以每个像素点为中心的$10 \times 10$邻域被用来训练Cs-CNN,损失函数采用facal loss。然后将Cs-CNN的权重迁移到C-Dailated CNN中,可以在较小精度损失情况下实现pixel mapping。然后将Cs-CNN权重迁移到CRPM-Net中。最后,基于C-Dailated CNN获得的dense score map和high-weighted training pixels,对CRPM-Net的decoder部分进行训练,以获取上下文语义特征,并对Cs-CNN和C-Dailated CNN的误分类像素进行纠正。和Cs-CNN 和 C-Dilated CNN相似,这样将得到的复数特征图拆分成实数部分、虚数部分、幅度部分、相位部分,然后紧跟一个$4 \times num_classes$的全连接层得到每一个类别的得分,采用交叉熵计算损失并更新decoder部分。
实验结果
这里作者使用了好几个数据集,我只挑出其中的一个数据集进行说明。
在输入到网络之前,作者先使用了refined Lee algorithm对协方差矩阵$C$进行了处理。作者将复数域的网络和实值网络进行了对比。网络分别为CNN、Dilated CNN、 RPM-Net和 C-Dilated CNN、CRPM-Net。为了对比更加公平,作者保持实值网络和复数网络的DoF(the freedom of degree)一致。
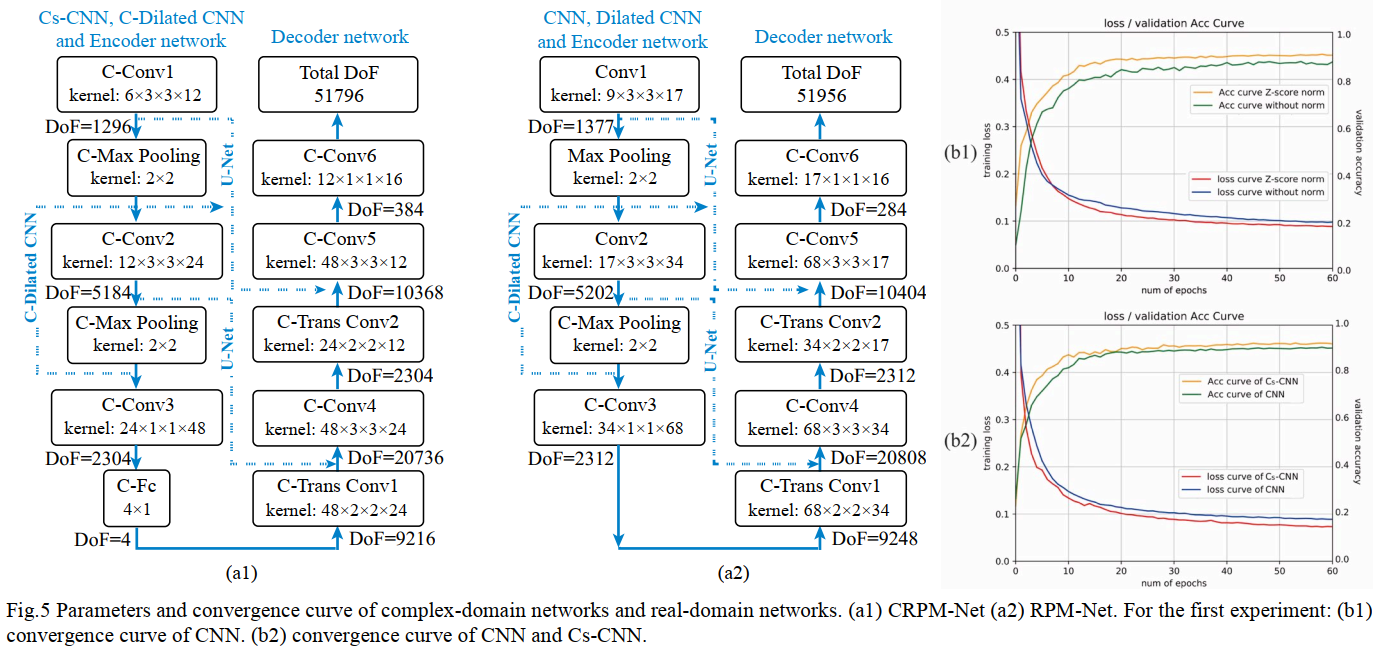
其中实值网络的输入为9维实数向量:
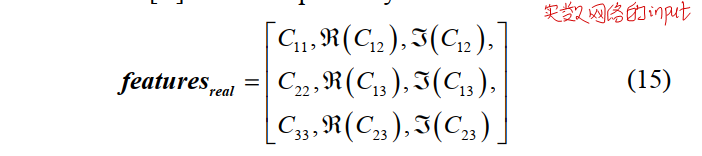
复数网络的输入为6维复数向量:$features_{imag}=[ C’_{11},C’_{22},C’_{33},C’_{12},C’_{13},C’_{23}]$,其中$C_{11}、C_{22}、C_{33}$的虚数部分为$10^{-8}$。另外,每个维度都采用了标准化,表达式如下:
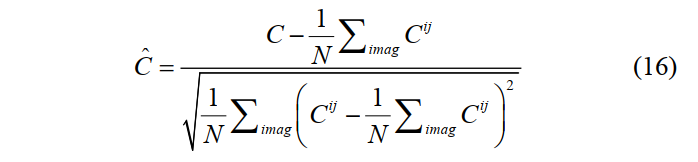
从图5(b1)可以看到,经过标准化后收敛速度更快切更加精准。从图5(b2)可以看到,复数神经网络的收敛速度更快切更加精准。
对于Flevoland-Netherlands区域,其图像大小为$1279 \times 1024$,包含16类,使用L,P,C通道合成pseudo RGB图以及其真实类别如下所示。其中,黑色的像素点是不参与实验的。

每个种类的样本数以及分类结果如下所示:
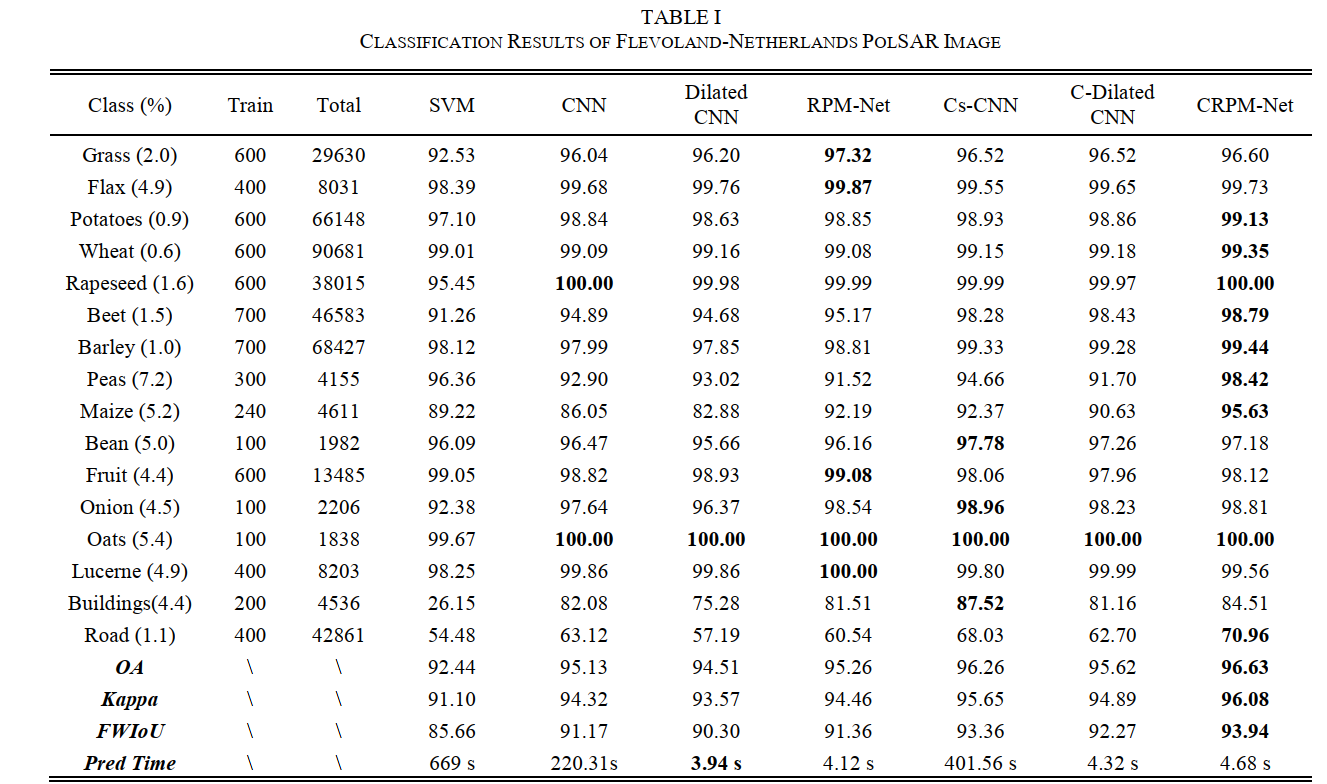
- 从表格中CNN和Cs-CNN两列来看,CNN的准确率比Cs-CNN的OA、Kappa大概都要低1.1%。然而,Cs-CNN的分类速度是CNN的大概两倍
- 直接将Cs-CNN的权重迁移到C-Dilated CNN中,OA大概下降了0.63%,但是后者的速度比CNN还要快90倍
- CRPM-Net实现了最好的分类精度,且在整张图上耗时4.68秒,比Cs-CNN快了83倍,比C-Dilated CNN慢了0.6秒。
总结
作者从pixel by pixel的方式比较耗时,而pixel mapping network的方法高效,但是因ground truth缺失而导致分类不够精准的角度出发。
- 首先训练了一个pixel by pixel的网络Cs-CNN
- 然后将权重迁移到C-Dilated CNN,实现pixel mapping分类,此时虽然解决了分类耗时的问题,但是精度下降了
- 为了进一步解决这个问题,引入了一个encoder-decoder网络,将Cs-CNN的权重迁移到encoder部分。然后将C-Dilated CNN和encoder-decoder网络结合,以便于实现更好的定位且有效的提取上下文信息。得到了CRPM-Net。以C-Dilated CNN的输出作为ground truth训练CRPM-Net,并使用真实类别对C-Dilated CNN的输出进行调整与加权。
若是直接将Cs-CNN迁移到encoder-decoder网络,则没有ground truth进行训练,所以这三部分缺一不可。
本文虽然开源了代码,但是代码写的很乱,而且缺失部分函数,完全跑不通,且感觉文内有部分错误。思路虽然麻烦,但是感觉还是有借鉴意义的。

